Эта статья будет дополнением к предыдущей (https://pcpro100.info/skanirovanie-teksta/), и более детально раскроет суть непосредственного распознавания текста.
Эта статья будет дополнением к предыдущей (https://pcpro100.info/skanirovanie-teksta/), и более детально раскроет суть непосредственного распознавания текста.
Начнем с самой сути, которую многие пользователи не до конца понимают.
После сканирования книги, газеты, журнала и пр. вы получаете набор картинок (т.е. графические файлы, а не текстовые), которые нужно распознать в специальной программе (одна из лучших для этого — ABBYY FineReader). Распознание — это и есть, процесс получения текста из графики и именно этот процесс мы и распишем более детально.
В своем примере сделаю скриншот этого сайта и попробую получить с него текст.
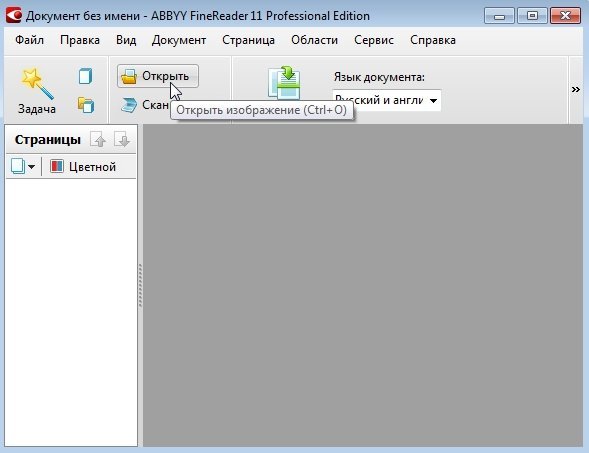
1) Открытие файла
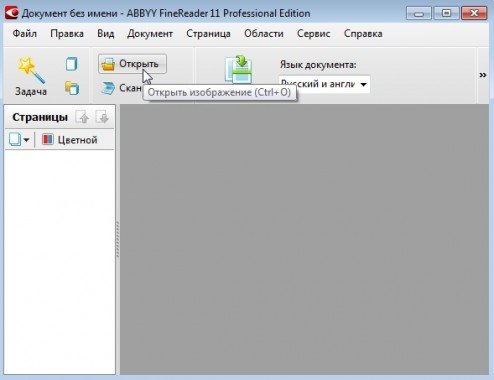
Открываем картинку(и), которые планируем распознать.
Кстати, здесь нужно отметить, что открыть можно не только форматы картинок, но и, например, файлы DJVU и PDF. Это позволит быстро распознать целую книгу, которые по сети, обычно, распространяются именно в этих форматах.
2) Редактирование
Сразу соглашаться с авто-распознаванием большого смысла нет. Если, конечно, у вас книга в которой только текст, нет картинок и табличек, плюс отсканирована в отличном качестве, то можете. В остальных случаях, лучше все области задать вручную.
Обычно сначала нужно удалить со страницы ненужные области. Для этого нажмите на панеле кнопку редактировать.
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2014-01-02_17-46-29](https://pcpro100.info/wp-content/uploads/2014/01/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2014-01-02_17-46-29-500x366.jpg)
Затем нужно оставить только ту область, с которой вы хотите дольше работать. Для этого есть инструмент обрезки ненужных границ. Справа в колонке выберите режим обрезать.
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2014-01-02_17-46-59](https://pcpro100.info/wp-content/uploads/2014/01/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2014-01-02_17-46-59-241x380.jpg) Далее выделите область, которую хотите оставить. На картинке снизу она выделена красным.
Далее выделите область, которую хотите оставить. На картинке снизу она выделена красным.
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2014-01-02_17-47-06](https://pcpro100.info/wp-content/uploads/2014/01/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2014-01-02_17-47-06.jpg) Кстати, если у вас открыто несколько картинок, то обрезку можно применить ко всем изображениям сразу! Удобно, чтобы не резать каждую по отдельности. Обратите внимание, внизу этой панельки есть еще один замечательный инструмент — ластик. При помощи него с картинки можно стереть ненужные разводы, номера страниц, крапинки, ненужные спец-символы и отдельные участки.
Кстати, если у вас открыто несколько картинок, то обрезку можно применить ко всем изображениям сразу! Удобно, чтобы не резать каждую по отдельности. Обратите внимание, внизу этой панельки есть еще один замечательный инструмент — ластик. При помощи него с картинки можно стереть ненужные разводы, номера страниц, крапинки, ненужные спец-символы и отдельные участки.
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2014-01-02_17-47-12](https://pcpro100.info/wp-content/uploads/2014/01/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2014-01-02_17-47-12-230x380.jpg)
После того, как вы нажмете обрезать края, исходная ваша картинка должна измениться: останется только рабочая область.
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2014-01-02_17-47-19](https://pcpro100.info/wp-content/uploads/2014/01/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2014-01-02_17-47-19.jpg) Дальше можете выходить из редактора изображений.
Дальше можете выходить из редактора изображений.![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2014-01-02_17-47-26](https://pcpro100.info/wp-content/uploads/2014/01/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2014-01-02_17-47-26.jpg)
3) Выделение областей
На панельке, над открытой картинкой, есть небольшие прямоугольники, которые задают области сканирования. Их несколько, рассмотрим кратко самые распространенные.
Картинка — эту область программа не будет распознавать, она просто скопирует заданный прямоугольник и вставит его в распознанный документ.
Текст — главная область, на которой сосредоточиться программа и попытается из картинки получить текст. Эту область мы и выделим в нашем примере.
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2014-01-02_17-47-39](https://pcpro100.info/wp-content/uploads/2014/01/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2014-01-02_17-47-39-500x377.jpg) После выделения, область закрашивается в светло-зеленый цвет. Далее можно переходить к следующему шагу.
После выделения, область закрашивается в светло-зеленый цвет. Далее можно переходить к следующему шагу.
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2014-01-02_17-47-50](https://pcpro100.info/wp-content/uploads/2014/01/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2014-01-02_17-47-50-494x380.jpg)
4) Распознавание текста
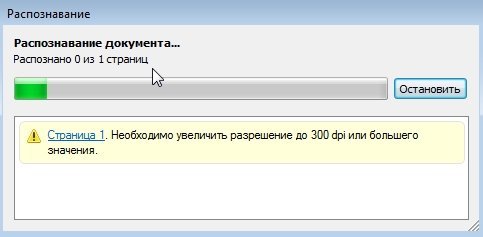
После того, как все области заданы, щелкайте в меню команду распознать. К счастью, в этом шаге больше ничего делать ненужно.
Время распознавания зависит от количества страниц в вашем документе и мощности компьютера.
В среднем на одну полную страницу, отсканированную в хорошем качестве уходит 10-20 сек. на среднем по мощности ПК (по сегодняшним меркам).
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2014-01-02_17-47-55](https://pcpro100.info/wp-content/uploads/2014/01/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2014-01-02_17-47-55.jpg)
5) Проверка ошибок
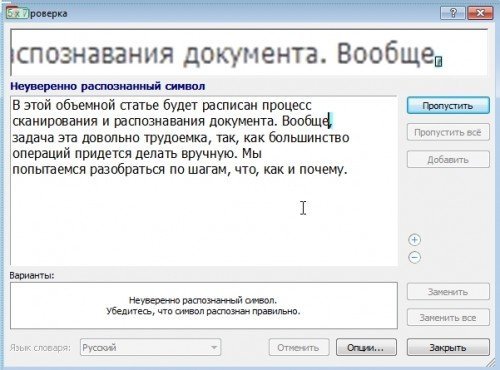
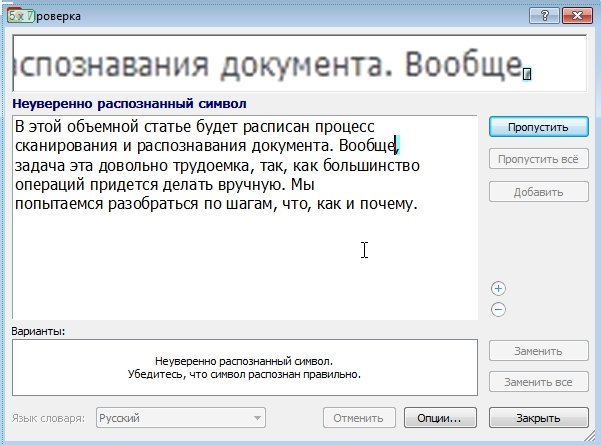
Каким бы не было исходное качество картинок, обычно всегда после распознавания остаются ошибки. Все таки пока ни одна программа не способна полностью исключить работу человека.
Нажимайте на опцию проверки и ABBYY FineReader начнет выводить вам поочередно те места в документе, где у него возникли запинки. Ваша задача, сравнив оригинал картинки (кстати, это место он вам покажет в укрупненном варианте) с вариантом распознания — ответить утвердительно, либо исправить и утвердить. Далее программа перейдет к следующему сложному месту и так далее, пока не будет проверен весь документ.
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2014-01-02_17-48-23](https://pcpro100.info/wp-content/uploads/2014/01/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2014-01-02_17-48-23-500x180.jpg)
Вообще, процесс этот может быть долгим и скучным…
6) Сохранение
ABBYY FineReader предлагает несколько вариантов сохранения вашей работы. Самый часто-используемый — это «точная копия». Т.е. весь документ, текст в нем, будет так же отформатирован, как и в исходнике.Удобный вариант для того, чтобы передать его в Word. Так мы и поступили в этом примере.
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2014-01-02_17-48-38](https://pcpro100.info/wp-content/uploads/2014/01/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2014-01-02_17-48-38-500x109.jpg)
После этого вы увидите свой распознанный текст в привычном документе Word. Думаю, дальше расписывать что с ним делать, большого смысла нет…
Таким образом мы на конкретном примере разобрали, как можно перевести картинку в обычный текст. Процесс этот не всегда простой и быстрый.
В любом случае, все будет зависеть от исходного качество картинки, вашего опыта и скорости работы компьютера.
Удачной работы!
Оцените статью:
(5 голосов, среднее: 4 из 5)
Поделитесь с друзьями!

![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2014-01-02_17-46-29](https://pcpro100.info/wp-content/uploads/2014/01/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2014-01-02_17-46-29.jpg)
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2014-01-02_17-46-59](https://pcpro100.info/wp-content/uploads/2014/01/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2014-01-02_17-46-59.jpg)
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2014-01-02_17-47-12](https://pcpro100.info/wp-content/uploads/2014/01/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2014-01-02_17-47-12.jpg)
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2014-01-02_17-47-39](https://pcpro100.info/wp-content/uploads/2014/01/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2014-01-02_17-47-39.jpg)
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2014-01-02_17-47-50](https://pcpro100.info/wp-content/uploads/2014/01/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2014-01-02_17-47-50.jpg)
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2014-01-02_17-48-23](https://pcpro100.info/wp-content/uploads/2014/01/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2014-01-02_17-48-23.jpg)
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2014-01-02_17-48-38](https://pcpro100.info/wp-content/uploads/2014/01/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2014-01-02_17-48-38.jpg)